(Or: Enforced Algebraic Structure of Commutative Accumulative Hash Functions)
While there are several documented approaches to defining a hash function for lists and other containers where iteration order is guaranteed, there seems to be less discussion around best practices for defining a hash function for unordered containers. One obvious approach is to simply sum 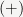
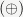
Hash functions are usually valued in unsigned 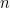
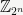


and a global constant starting value 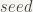

hash(c):
ret = seed
for t in c:
ret = h(ret, hash(t))
return ret
There are many examples of this pattern for ordered containers, such as lists:
- Boost Library’s hash_combine function follows this pattern, with
1
- In Java, the hash code for lists and strings follows this pattern with
- More generally, hashes for an arbitrary block of bytes sometimes follow this approach as well. For example
- The Fowler-Noll-Vo hash functions FNV-1 and FNV-1a use
respectively, where
is a specially chosen prime depending on the number of bits
.
- The Murmur family of hashes nearly fit into this pattern as well, where both the accumulator and individual hashes are some composition of invertible mixing functions, such as bit rotations, XORing with bit rotations, and addition or multiplication by a constant.
- The Fowler-Noll-Vo hash functions FNV-1 and FNV-1a use

A useful property of container hashes following this pattern is that they are incrementally updated: if one knows the current hash of the container, the hash after inserting (and in some cases, deleting) an element can be quickly computed by plugging the right values into the accumulator. Note that this is not possible in some versions of Murmur where the initial
Now let’s turn to unordered containers. If one wants to follow the template above, the hash accumulator will need the additional property of
(Commutativity) 
In existing libraries, the offerings are more modest.
- The Boost documentation advises one to choose a canonical ordering of the elements and use the existing order-dependent hash_combine function.
- Java’s Sets and Maps have a Hashcode method defined as the sum of the individual hashes of the elements.
- Although one can easily check that addition satisfies (Commutativity), it is problematic for Integers, as their default hash is the identity function. So, for example, the sets
and
will have the same hash. This issue can be overcome by using an avalanching hash for the Integer type.
- More seriously, if an individual element of a given type hashes to zero, then inserting or removing it from any container will not alter the container’s hash.
- Although one can easily check that addition satisfies (Commutativity), it is problematic for Integers, as their default hash is the identity function. So, for example, the sets
- An alternative to summing is proposed in https://www.preprints.org/manuscript/201710.0192/v1. Unfortunately, in the notation of that paper, we run into the same issue for elements which hash to
: an arbitrary number of such elements can be inserted or removed from a container without changing the container’s hash.
These issues stand in contrast to the accumulators used in ordered containers: taking Boost’s accumulator,

we see that although for any fixed 


So is there a commutative hash accumulator which avoids this degenerate behavior? The answer, under the right assumptions, is no. In fact, something even stronger holds.
Let us fix notations. Let

be a hash accumulator and 

denote the curry of 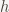
 .
.If we want to be able to incrementally update the hash of the container upon removal of an element, we will need the additional property of
(Invertibility)

Let 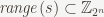

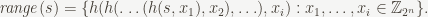
For the purposes of analyzing the usefulness of the hash accumulator, we only care about its behavior on 


where 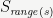

Main Proposition.
- If
with
containing the image of
.
- If
, and the image of
is simply the binary operation for some group structure on
- If
such that
for all
.2
Proof: The third point follows immediately from the second by taking
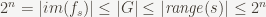
must all be equalities.
Now, let 





It remains to show 

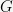

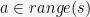






N.b. The group structure implied by the Proposition need not be the usual addition on 

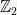
Exercise: Show that any abelian group of order
So what’s the takeaway?
If you want a commutative accumulative hash function that does not have these degenerate “no-op” elements, you will have to violate one of the assumptions we made. One possibility is to remove the assumption that the hash accumulator can only depend on the 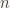




Thanks to Jason Sundram for feedback on an earlier version of this post.
Footnotes
1. See this question if you’re curious about where the magic constant 2654435769 comes from.
2 . The assumption that 
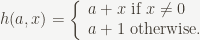
3. See BiggerHash for a bare-bones implementation with 


Thanks for sharing this article — very helpful!
LikeLike