In this post, we’re going to investigate an underexplored bridge between computer science and algebraic number theory. To motivate it, consider the analogy between floating point arithmetic and the theoretical real numbers. While floating points can only approximate the precision of a real number, much of what is rigorously established in the theoretical world carries over to the computational world. For example, the chain rule from calculus powers backpropagation of neural nets, and the spectral theorem from linear algebra plays a key role in principal component analysis. Here we are concerned with a similar analogy which applies to integer types rather than floating point types.
double: 
int: (?)

One obvious theoretical candidate is the ring of integers 
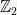
Our motivation for using this space is that 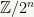
Another nice property of 
Now fix a choice of 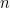
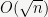
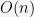

Theoretical Background
Before giving a precise definition, we’ll state some properties of
The first thing to understand about a function is its domain and range. In most textbooks on p-adic analysis, the 2-adic logarithm would be defined on the entire space of 2-adic numbers. However, since we are trying to do actual computations, we will instead fix an integer
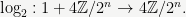
That is, the domain of 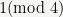
01, and its range is the set of integers congruent to 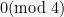
00.
The 2-adic exponential has the opposite function signature:
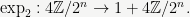
Together, these two functions satisfy the inversion formulas
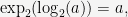

on their respective domains. They also obey the same sum-product identities as the usual exponential and logarithm:


N.b. We are using modulo addition and multiplication for n-bit integers.
Putting this in more theoretical language, 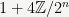

Aside: So far this all sounds vaguely similar to the usual logarithm and exponential, and our choice of n is analogous to choosing the number of bits of precision in the floating point world. A crucial difference is that both the inversion and sum-product formulas are exact even after we have fixed n. Contrast this with the world of floats where even simple operations like addition incur rounding errors.
So how does this help with our exponentiation and root algorithms? First note that the sum identity above immediately implies
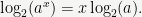
Thus, when 
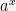
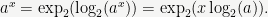
One can extend this to all 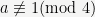


Summarizing, we have “reduced” the integer exponential calculation to an 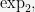

Precise Definitions
Now that we’ve seen how these functions plug into our algorithm, let’s actually define them. In short, they are defined by the usual convergent Taylor series:
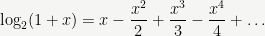

where 
Those fractions don’t look like integers. For odd integers in the denominator, the division is really a shorthand for multiplication by the 2-adic multiplicative inverse. For powers of two in the denominator, we do mean the usual notion of division, but our assumption that 

What does “convergent” mean in this context? The convergence here is with respect to the 
To give a few concrete examples, for


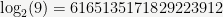
as numbers modulo 264.
How many terms do we actually need to compute? That depends on 

- The exponent of the largest power of 2 which divides
- Equivalently, the number of trailing zeros in the base-2 representation of
In typical mathematical conventions, 
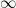
ctz and its variants offered by many modern CPU architectures computes 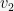
This function has the following properties:





In this notation, we only need to include the terms of the Taylor series for which 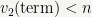
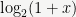
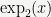

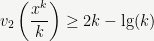
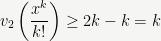
Exercise: Prove these estimates using the above properties.
From here, one can estimate that 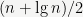
More generally, if 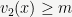
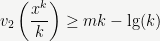
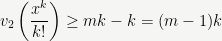
in which case 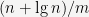


The Code
First Pass
Now that we have laid the theoretical foundation, we can start working on an implementation. For simplicity, we will now assume
Great! So we’ve effectively turned exponentiation into multiplication via a pair of functions which… each require over 50 multiplications. Hm. Not great. The problem is that the number of terms of the Taylor series is proportional to the number of bits, and each additional term typically requires one or two additional multiplies3. In the next section, we’ll see how to cut this number down.
Optimizing the number of terms
The key observation is that the number of terms we need to compute depends greatly on our assumption that
One way to achieve this it to use a lookup table to adjust the lower order bits of
First, pre-compute
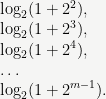
Then, at runtime, if 
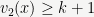
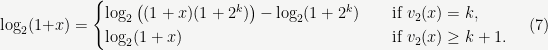
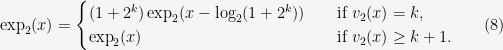
Exercise: Show that if 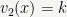
.
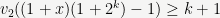
In both cases, we are able to bump up the valuation of 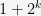
Now how do we choose the number of lookups 
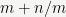
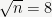
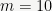
The code for the optimized power function can be found here, alongside a basic implementation of the power function using repeated squaring.
One last optimization
Before we get to the benchmarks, there is one more optimization to make that is specific to the exponentiation problem, which is to combine ingredients from the repeated squaring and 2-adic approaches. Namely, instead of using a lookup table to compute
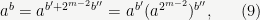
where 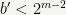
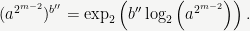
However, in general when
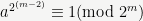
Thus, both
The code for this combined approach is here.
Benchmarks
Now that we have something a bit more reasonable, let’s put it to the test on the exponentiation problem mentioned at the beginning, comparing to the usual approach of repeated squaring. Our benchmark takes a random 64-bit integer as the exponent and a random odd 64-bit integer as the base. An even base will almost always exponentiate to zero, which unfairly benefits the 2-adic power function as it will return early.
The benchmark code can be found here. For the task of computing 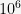
Standard: 591ms
Adic: 266ms
Combined: 151msClosing Thoughts
We have seen that leveraging 2-adic analytic techniques can pay dividends in the computational world. Although we initially set our sights on optimizing a specific computational task, we hope that this exposition makes a compelling case that there is more to be explored in this area.
For example, nearly everything we’ve talked about can be generalized to arithmetic modulo 
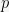

We conclude with a few open questions:
. What is the true minimum complexity of
- See also footnote 3 below.
- Can the cases
be handled more elegantly? Is there an efficient branchless implementation of
- In the extreme case where
, we only need up to the linear term of the Taylor series for

Thanks to Nathan Bronson for feedback on an earlier version of this post.
Footnotes
1The benchmarks and complexity analysis are done for randomly chosen 
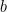
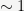
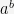
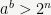
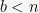

2Any nonzero integer can be written uniquely as 
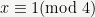
3It is not obvious or even true in general that the number of multiplications required to compute a partial Taylor series is linear in the number of terms. For example, one can compute the partial sum of the first 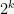
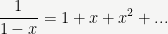
in only 
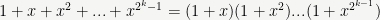
If

In view of your question on the asymptotic complexity of 2-adic powering, I think you might be interested in Section 3 of this draft we just put online: .
LikeLike